portfolio
Bita Ashoori
💼 Data Engineering Portfolio
Designing scalable, cloud-native data pipelines that power decision-making across healthcare, retail, and public services.

About Me
I’m a Data Engineer based in Vancouver with over 5 years of experience spanning data engineering, business intelligence, and analytics. I specialize in designing cloud-native ETL/ELT pipelines and automating data workflows that transform raw data into actionable insights.
My background includes work across healthcare, retail, and public-sector environments, where I’ve delivered scalable and reliable data solutions. With 3+ years building cloud data pipelines and 2+ years as a BI/ETL Developer, I bring strong expertise in Python, SQL, Apache Airflow, and AWS (S3, Lambda, Redshift).
I’m currently expanding my skills in Azure and Databricks, focusing on modern data stack architectures—including Delta Lake, Medallion design, and real-time streaming—to build next-generation data platforms that drive performance, reliability, and business value.
Contact Me
🔗 Quick Navigation
- 🛒 Azure ADF Retail Pipeline
- 🏗️ End-to-End Data Pipeline with Databricks
- ☁️ Cloud ETL Modernization
- ⚗️ Herbal Products API ETL
- 🛠️ Airflow AWS Modernization
- ⚡ Real-Time Marketing Pipeline
- 🎮 Real-Time Player Pipeline
- 📈 PySpark Sales Pipeline
- 🏥 FHIR Healthcare Pipeline
- 🚀 Real-Time Event Processing with AWS Kinesis, Glue & Athena
- 🔍 LinkedIn Scraper (Lambda)
Project Highlights
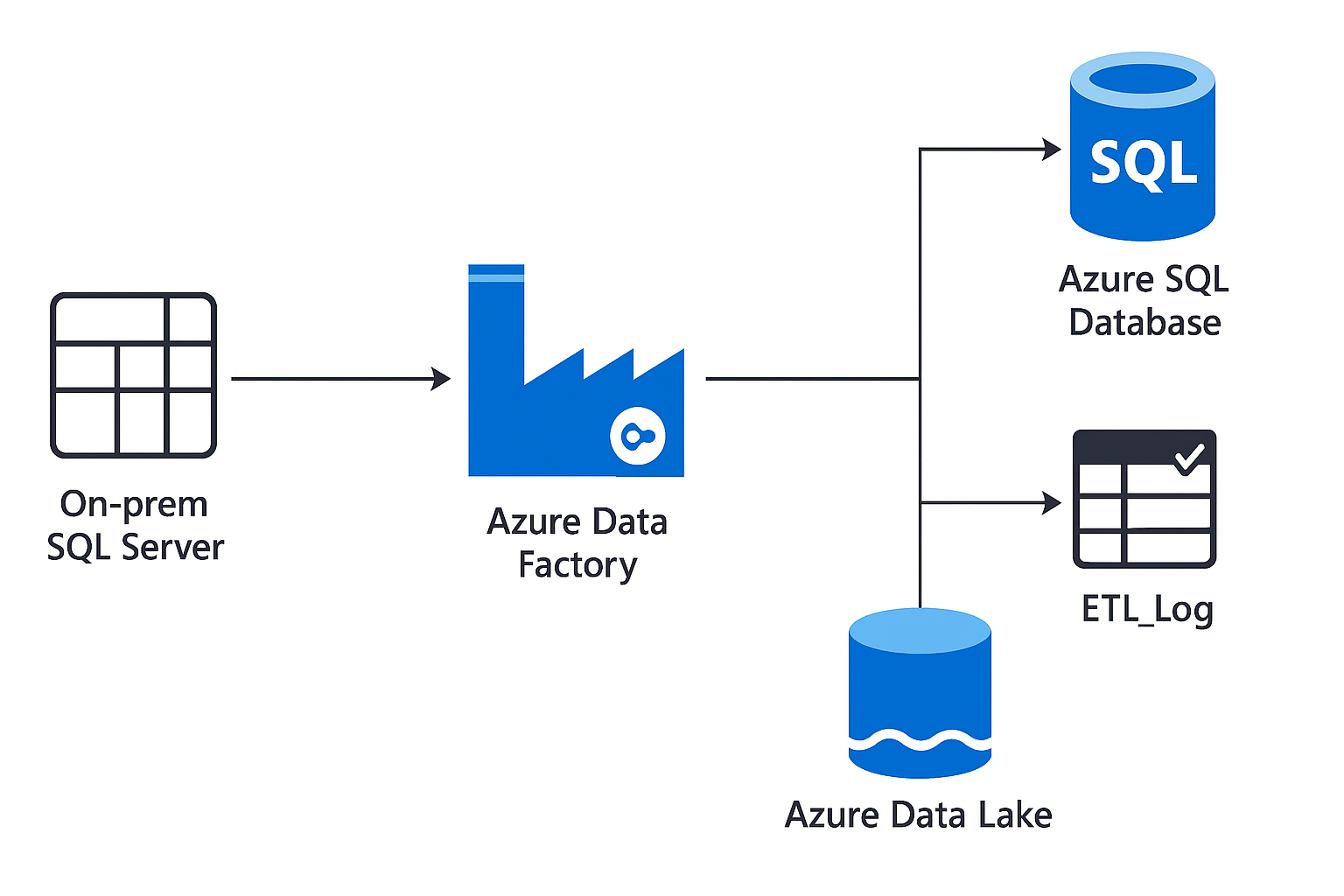
🛒 Azure ADF Retail Pipeline
Scenario: Retail organizations needed an automated cloud data pipeline to consolidate and analyze sales data from multiple regions.
📎 View GitHub Repo
Solution: Developed a cloud-native ETL pipeline using Azure Data Factory that ingests, transforms, and loads retail sales data from on-prem SQL Server to Azure Data Lake and Azure SQL Database. Implemented parameterized pipelines, incremental data loads, and monitoring through ADF logs.
✅ Impact: Improved reporting efficiency by 45%, automated data refresh cycles, and reduced manual dependencies.
🧰 Stack: Azure Data Factory · Azure SQL Database · Blob Storage · Power BI
🧪 Tested On: Azure Free Tier + GitHub Codespaces
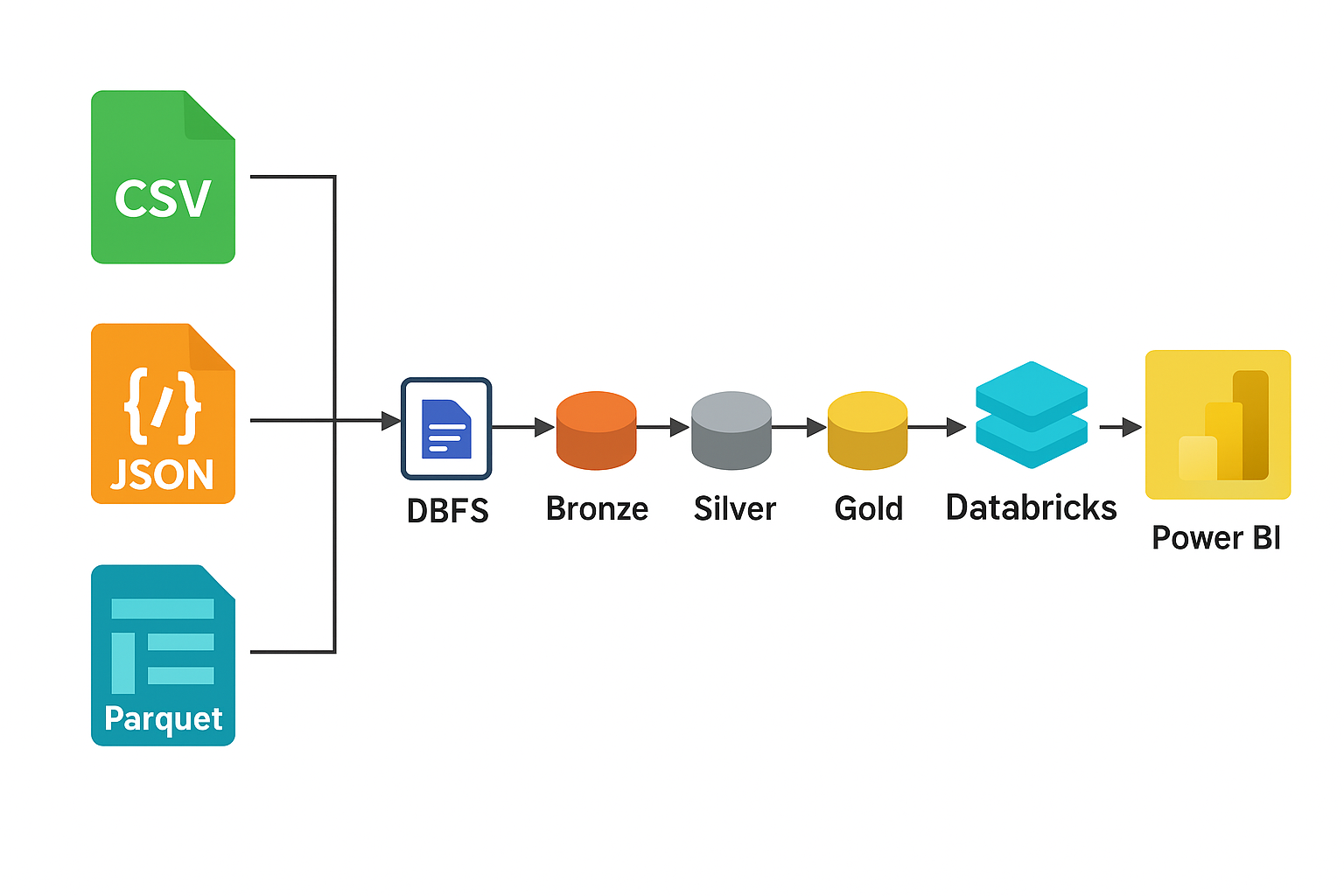
🏗️ End-to-End Data Pipeline with Databricks
Scenario: Designed and implemented a complete end-to-end ETL pipeline in Azure Databricks, applying the Medallion Architecture (Bronze → Silver → Gold) to build a modern data lakehouse for analytics.
📎 View GitHub Repo
Solution: Developed a multi-layer Delta Lake pipeline to ingest, cleanse, and aggregate retail data using PySpark and SQL within Databricks notebooks. Implemented data quality rules, incremental MERGE operations, and created analytical views for dashboards.
✅ Impact: Improved data reliability and reduced transformation latency by enabling efficient, governed, and automated data processing in the Databricks ecosystem.
🧰 Stack: Azure Databricks · Delta Lake · PySpark · Unity Catalog · Power BI
🧪 Tested On: Azure Databricks Community Edition + GitHub Codespaces
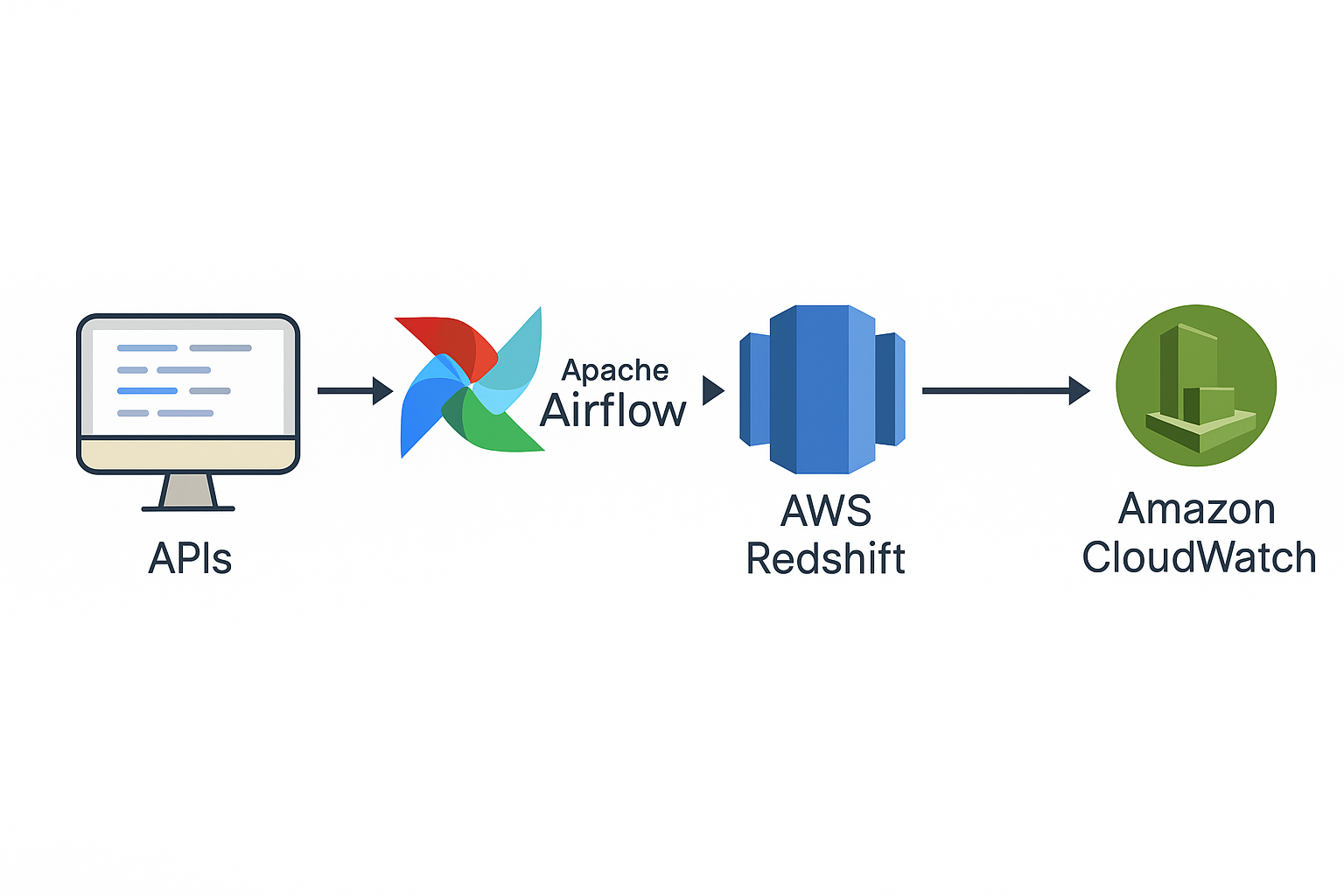
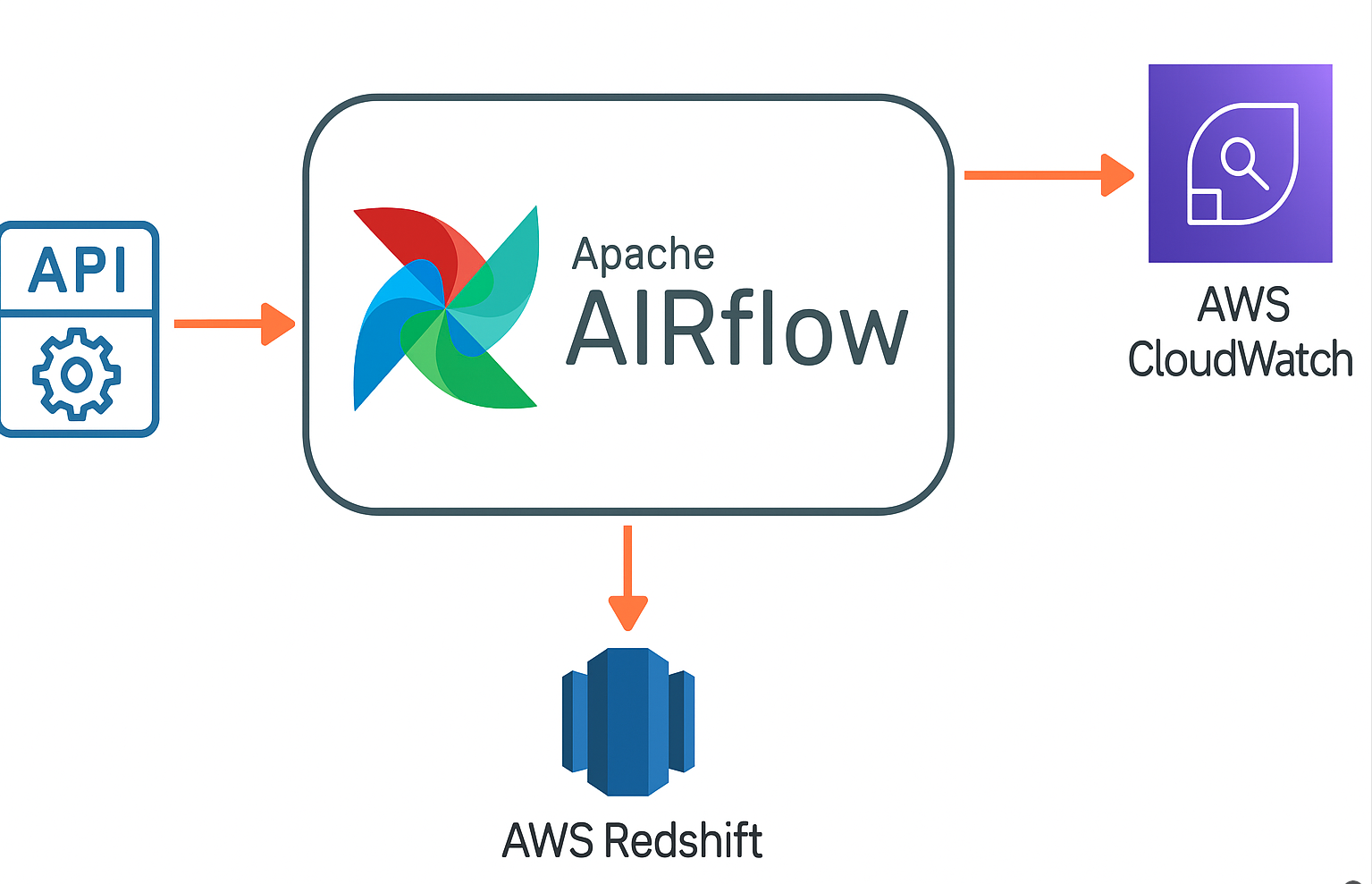
☁️ Cloud ETL Modernization
Scenario: Legacy workflows lacked observability, scalability, and centralized monitoring.
📎 View GitHub Repo
Solution: Built scalable ETL from APIs to Redshift with Airflow orchestration and CloudWatch alerting; standardized schemas and error handling.
✅ Impact: ~30% faster troubleshooting via unified logging/metrics; more consistent SLAs.
🧰 Stack: Apache Airflow · AWS Redshift · CloudWatch
🧪 Tested On: AWS Free Tier + Docker
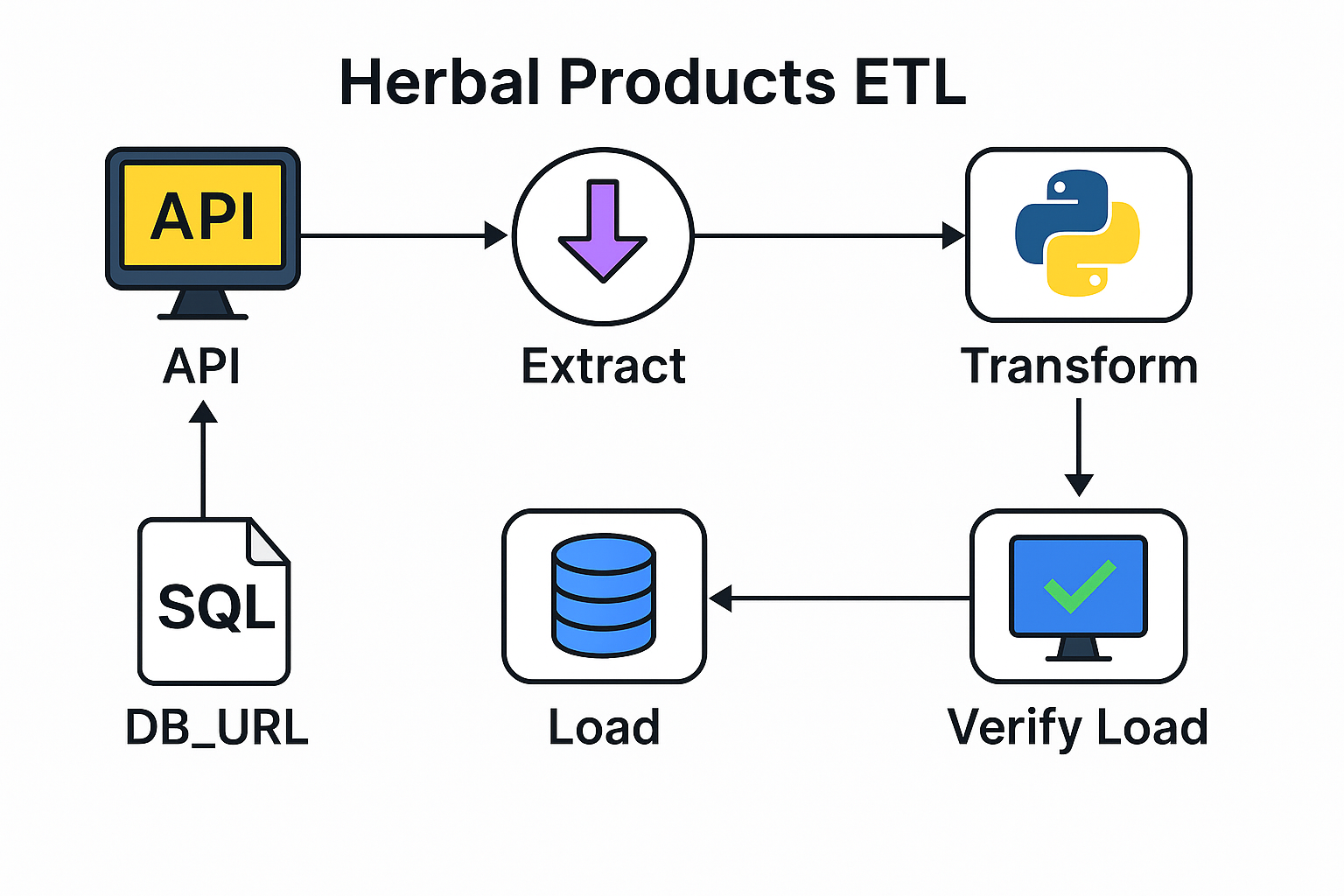
⚗️ Herbal Products API ETL (SQLite + Logging)
Scenario: Built a complete API-based ETL pipeline for a natural products company (simulated from Natural Factors) to extract, transform, and load product data into a local SQLite database for analysis and visualization.
📎 View GitHub Repo
Solution: Designed a modular ETL process in Python that connects to an external API, performs data cleaning, loads data into SQLite, and includes full logging, error handling, and ETL monitoring with Loguru. A Streamlit dashboard visualizes data for easy validation.
✅ Impact: Demonstrates production-style ETL workflow design, monitoring, and API integration within a lightweight, reproducible environment (GitHub Codespaces).
🧰 Stack: Python · SQLite · Pandas · Loguru · Streamlit · SQLAlchemy
🧪 Tested On: GitHub Codespaces + Local SQLite
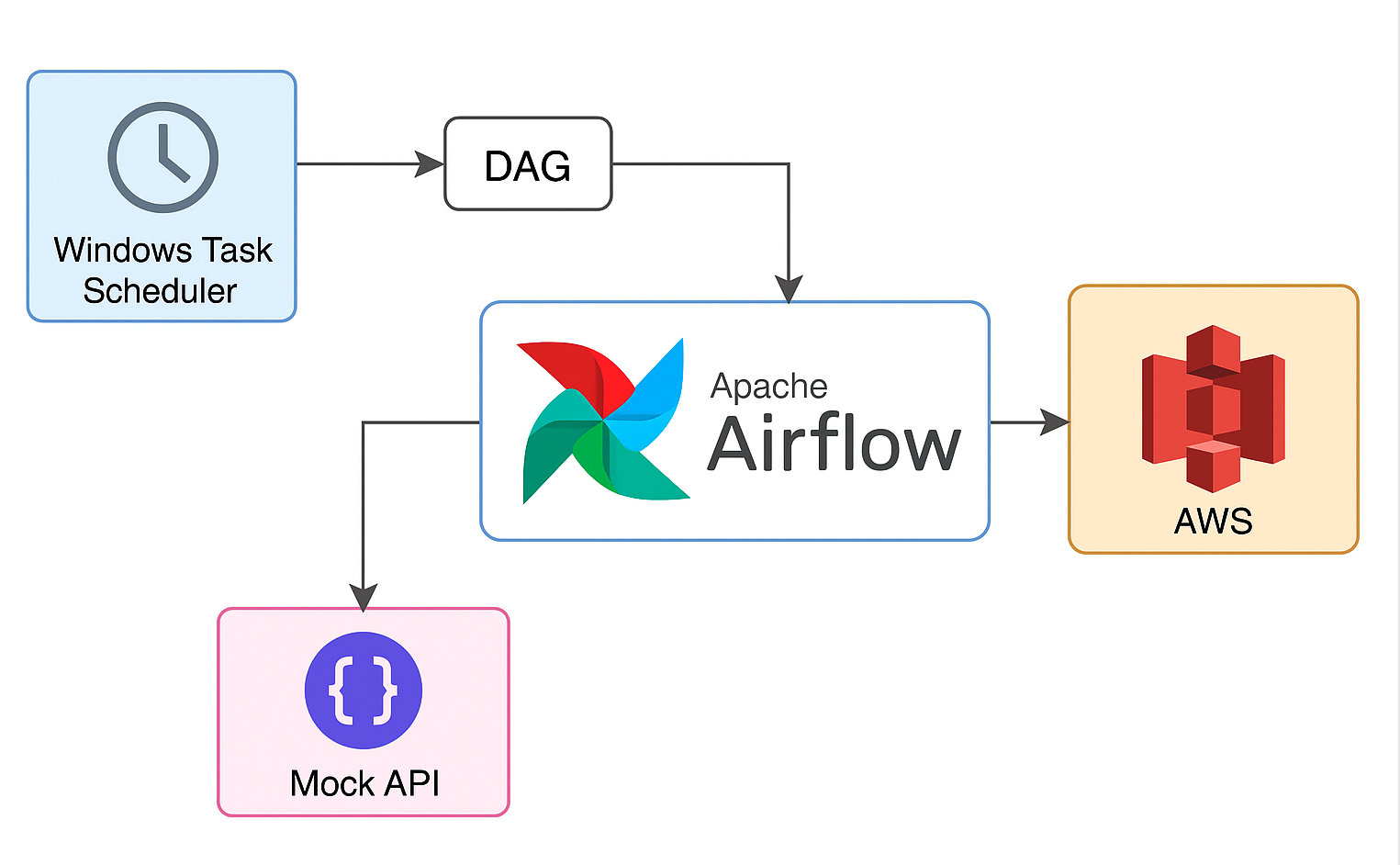
🛠️ Airflow AWS Modernization
Scenario: Legacy Windows Task Scheduler jobs needed modernization for reliability and observability.
📎 View GitHub Repo
Solution: Migrated jobs into modular Airflow DAGs containerized with Docker, storing artifacts in S3 and standardizing logging/retries.
✅ Impact: Up to 50% reduction in manual errors and improved job monitoring/alerting.
🧰 Stack: Python · Apache Airflow · Docker · AWS S3
🧪 Tested On: Local Docker + GitHub Codespaces
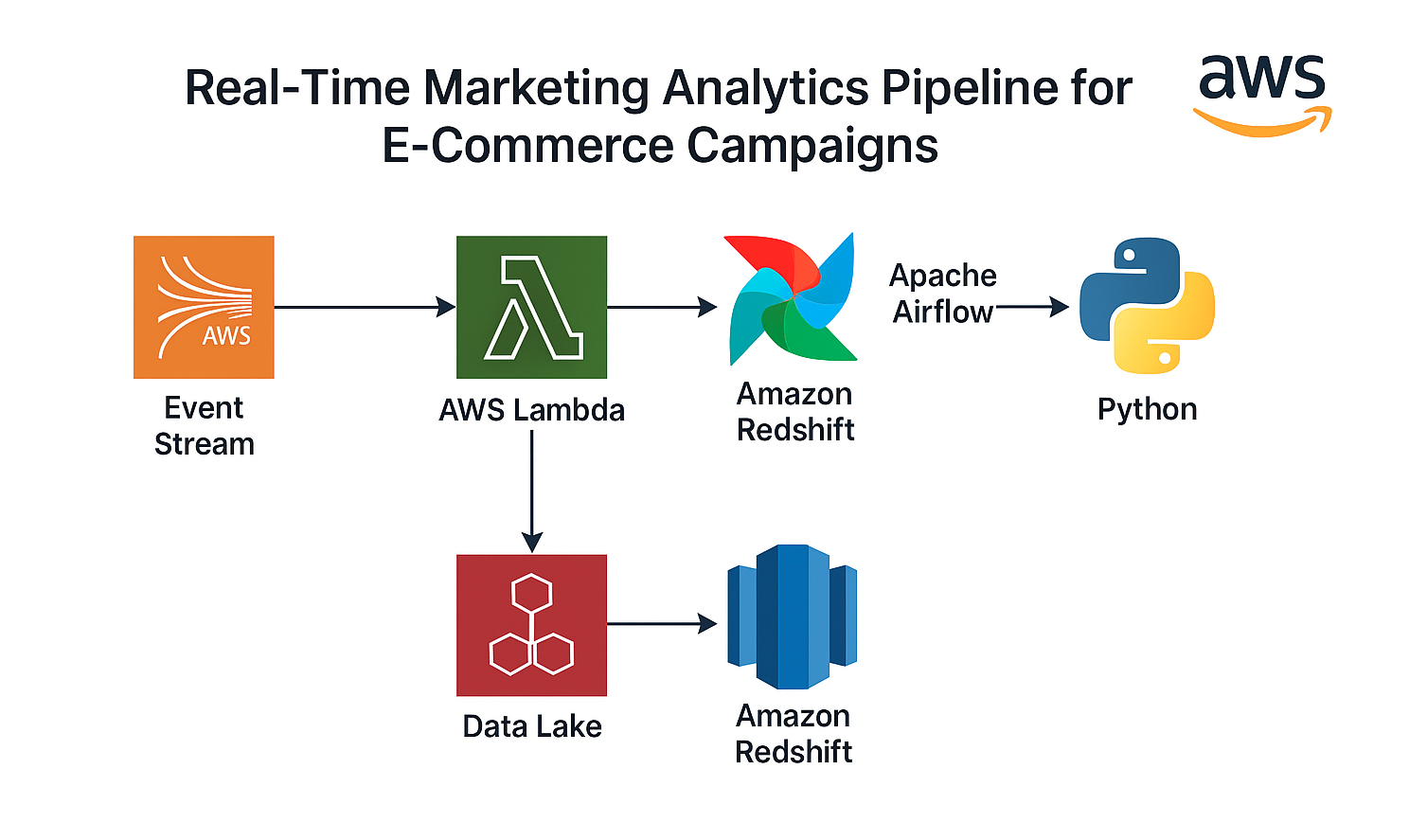
⚡ Real-Time Marketing Pipeline
Scenario: Marketing teams often struggle to get timely insights from campaign data spread across multiple ad platforms. This project simulates a real-time ingestion and transformation system to provide near-instant analytics for marketing performance.
📎 View GitHub Repo
Solution: Implemented a PySpark-based data ingestion and transformation pipeline that streams ad campaign data into a Delta Lake architecture. Leveraged incremental data loading and scheduled automation with GitHub Actions for CI/CD.
✅ Impact: Reduced data latency from 24 hours to under 1 hour, enabling rapid decision-making for campaign optimization.
🧰 Stack: PySpark · Databricks · Delta Lake · GitHub Actions · AWS S3
🧪 Tested On: Databricks Community Edition + GitHub CI/CD
🎮 Real-Time Player Pipeline
Scenario: Gaming companies need live insights into player behavior to improve engagement and retention. This project demonstrates how to process high-volume event streams from gameplay in real time.
📎 View GitHub Repo
Solution: Built a streaming data pipeline using Kafka (or AWS Kinesis) for real-time ingestion, orchestrated with Airflow. Transformed and stored event data in AWS S3 for analytics, allowing near-instant monitoring of user engagement metrics.
✅ Impact: Enabled dashboards with real-time player stats and reduced data availability lag from hours to seconds.
🧰 Stack: Kafka · AWS Kinesis · Airflow · S3 · Spark
🧪 Tested On: Local Docker + AWS Free Tier
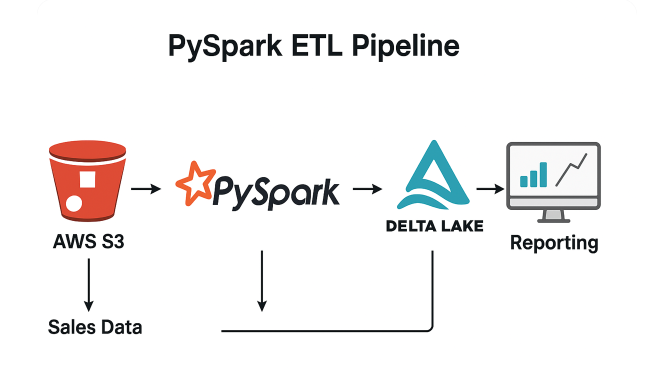
📈 PySpark Sales Pipeline
Scenario: Enterprises require efficient ETL systems to handle growing volumes of sales data and provide timely insights for forecasting and reporting.
📎 View GitHub Repo
Solution: Created a production-style PySpark ETL pipeline to extract large sales datasets, transform and aggregate them into a Delta Lake, and optimize with partitioning and caching for query performance.
✅ Impact: Achieved up to 40% faster transformations and improved report accuracy through standardized schema validation and Delta Lake optimization.
🧰 Stack: PySpark · Delta Lake · AWS S3 · Databricks
🧪 Tested On: Local Databricks + AWS Free Tier
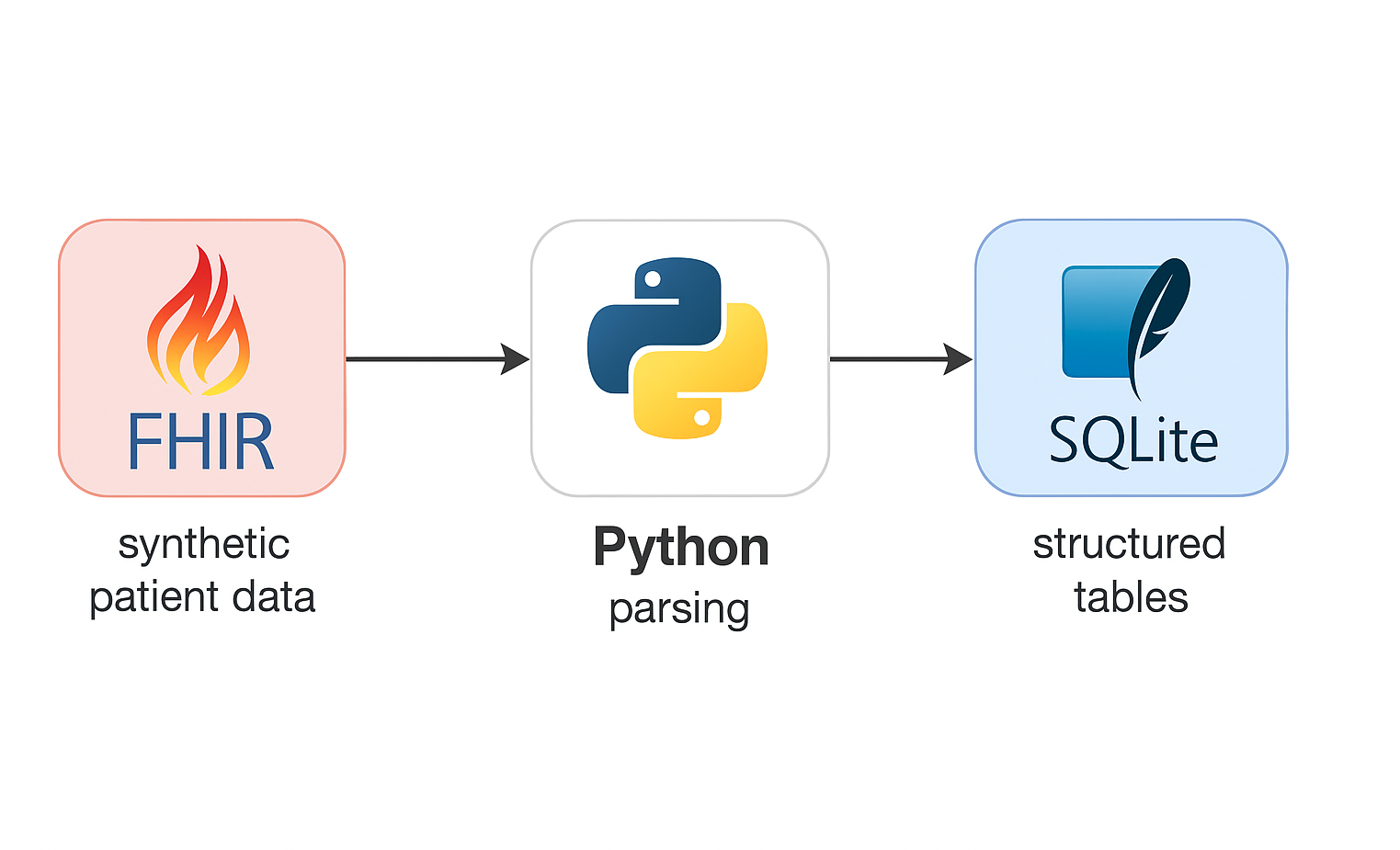
🏥 FHIR Healthcare Pipeline
Scenario: Healthcare organizations using FHIR (Fast Healthcare Interoperability Resources) often face data integration challenges between clinical systems and analytics tools.
📎 View GitHub Repo
Solution: Developed a Python-based ETL pipeline to ingest and normalize FHIR patient and encounter data, clean and store it in SQLite, and visualize it using Streamlit. Added validation and audit layers to ensure clinical data integrity.
✅ Impact: Improved preprocessing efficiency by 60% and ensured high-quality, analytics-ready clinical data.
🧰 Stack: Python · Pandas · FHIR API · SQLite · Streamlit
🧪 Tested On: Local + GitHub Codespaces
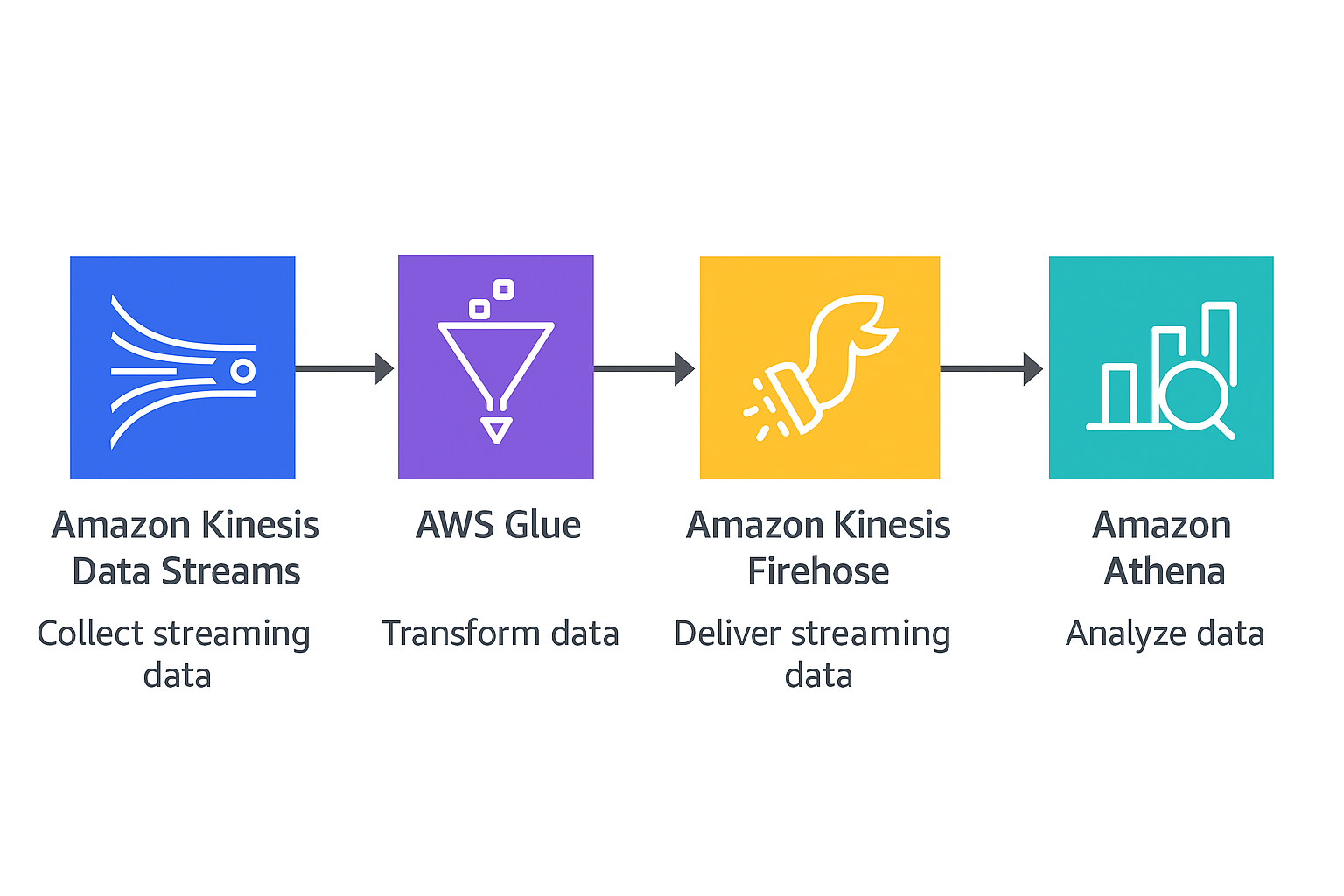
🚀 Real-Time Event Processing with AWS Kinesis, Glue & Athena
Scenario: Modern applications generate massive clickstream and interaction data that must be processed in near-real time for user analytics and system monitoring.
📎 View GitHub Repo
Solution: Designed an end-to-end data pipeline where user events are streamed to AWS Kinesis, transformed using Glue jobs, and queried via Athena. Implemented data cataloging and schema evolution for dynamic JSON data.
✅ Impact: Built a reusable real-time processing pattern for streaming analytics and data lake integration.
🧰 Stack: Python · AWS Kinesis · AWS Glue · AWS Athena · S3
🧪 Tested On: AWS Free Tier
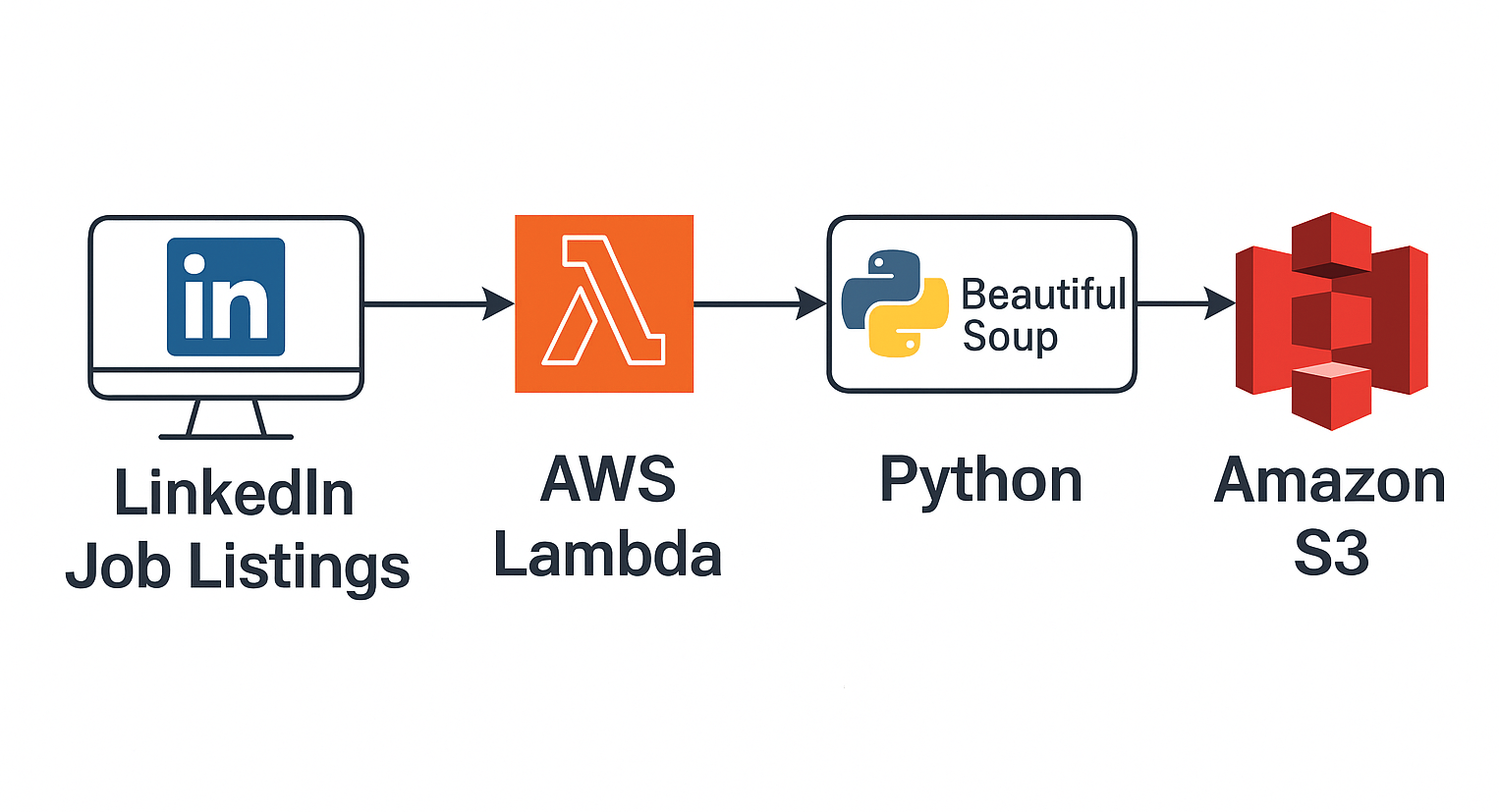
🔍 LinkedIn Scraper (Lambda)
Scenario: Manual job tracking is slow and error-prone for candidates, recruiters, and analysts seeking real-time market insights.
📎 View GitHub Repo
Solution: Created an automated data scraper using AWS Lambda and EventBridge that extracts LinkedIn job posts at scheduled intervals, parses them with BeautifulSoup, and stores them in S3 for analysis.
✅ Impact: Automated collection of job market data for trend analysis and dashboarding.
🧰 Stack: AWS Lambda · EventBridge · BeautifulSoup · S3
🧪 Tested On: AWS Free Tier + Local Validation