data-engineering-portfolio
Bita Ashoori
💼 Data Engineering Portfolio
Designing scalable, cloud-native data pipelines that power decision-making across healthcare, retail, and public services.

About Me
I’m a Data Engineer based in Vancouver with 5+ years of experience across data engineering, business intelligence, and analytics. I design cloud-native pipelines and automate workflows that turn raw data into actionable insights. My work spans healthcare, retail, and public-sector projects. With 3+ years building cloud pipelines and 2+ years as a BI/ETL Developer, I’m skilled in Python, SQL, Apache Airflow, and AWS (S3, Lambda, Redshift). Currently expanding my expertise in Azure data services and Databricks, alongside modern data stack practices, to build next-generation data platforms that support real-time insights and scalability.
Contact Me
🔗 Quick Navigation
- 🚀 Real-Time Event Processing with AWS Kinesis, Glue & Athena
- 🎮 Real-Time Player Pipeline
- 🛠️ Airflow AWS Modernization
- ☁️ Cloud ETL Modernization
- ⚡ Real-Time Marketing Pipeline
- 🏥 FHIR Healthcare Pipeline
- 📈 PySpark Sales Pipeline
- 🔍 LinkedIn Scraper (Lambda)
Project Highlights
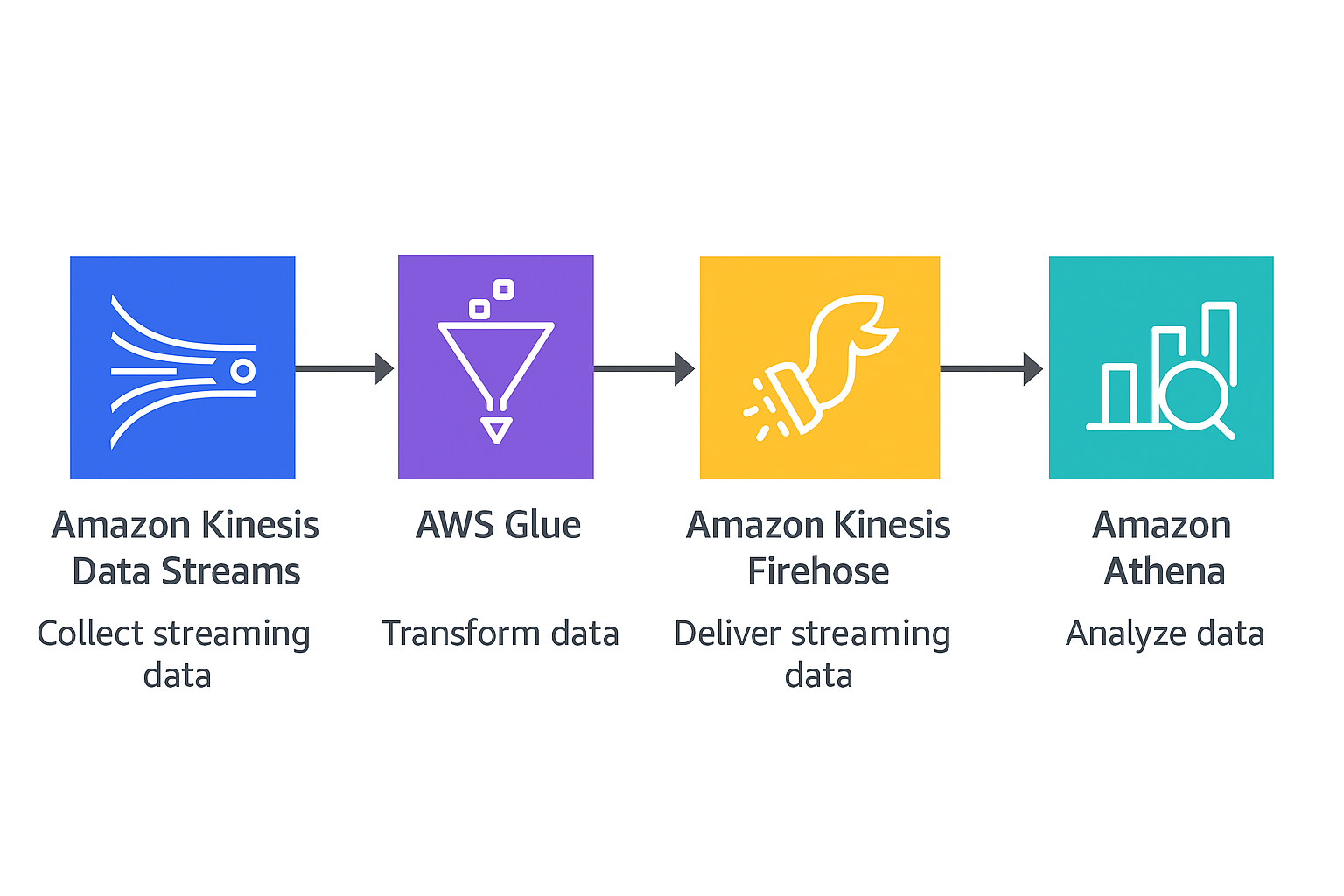
🚀 Real-Time Event Processing with AWS Kinesis, Glue & Athena
Scenario: Simulated a real-time clickstream pipeline where user interaction events (e.g., click, view, signup) are sent to AWS Kinesis, processed using AWS Glue, and queried using AWS Athena.
🧰 Stack: Python • AWS Kinesis • AWS Glue • AWS Athena • S3 • boto3 • .env • Shell
- Created a Kinesis data stream for ingesting clickstream data
- Sent sample events using Python &
boto3 - Stored incoming data in an S3 data lake
- Used Glue Crawlers to detect schema & create tables
- Queried results with SQL in Athena
- Set up partitioned & non-partitioned table comparisons
📊 Potential Impact: Scalable, real-time pipelines for product analytics, marketing, gaming, and clickstream use cases.
🧪 Tested On: GitHub Codespaces & AWS Console (Kinesis, Glue, S3, Athena)
 </p>
</p>
🎮 Real-Time Player Pipeline
Scenario: Gaming companies need real-time analytics on player activity to optimize engagement, matchmaking, and monetization.
📎 View GitHub Repo
Solution: Simulated streaming of player events into a data lake with transformations and aggregations to deliver analytics-ready datasets for dashboards and retention analysis.
✅ Impact: Reduced reporting lag from hours to seconds, enabling near real-time insights for live ops decisions.
🧰 Stack: Apache Kafka (or AWS Kinesis), AWS S3, DynamoDB, Apache Airflow, Spark
🧪 Tested On: Local Kafka, AWS Localstack, GitHub Codespaces
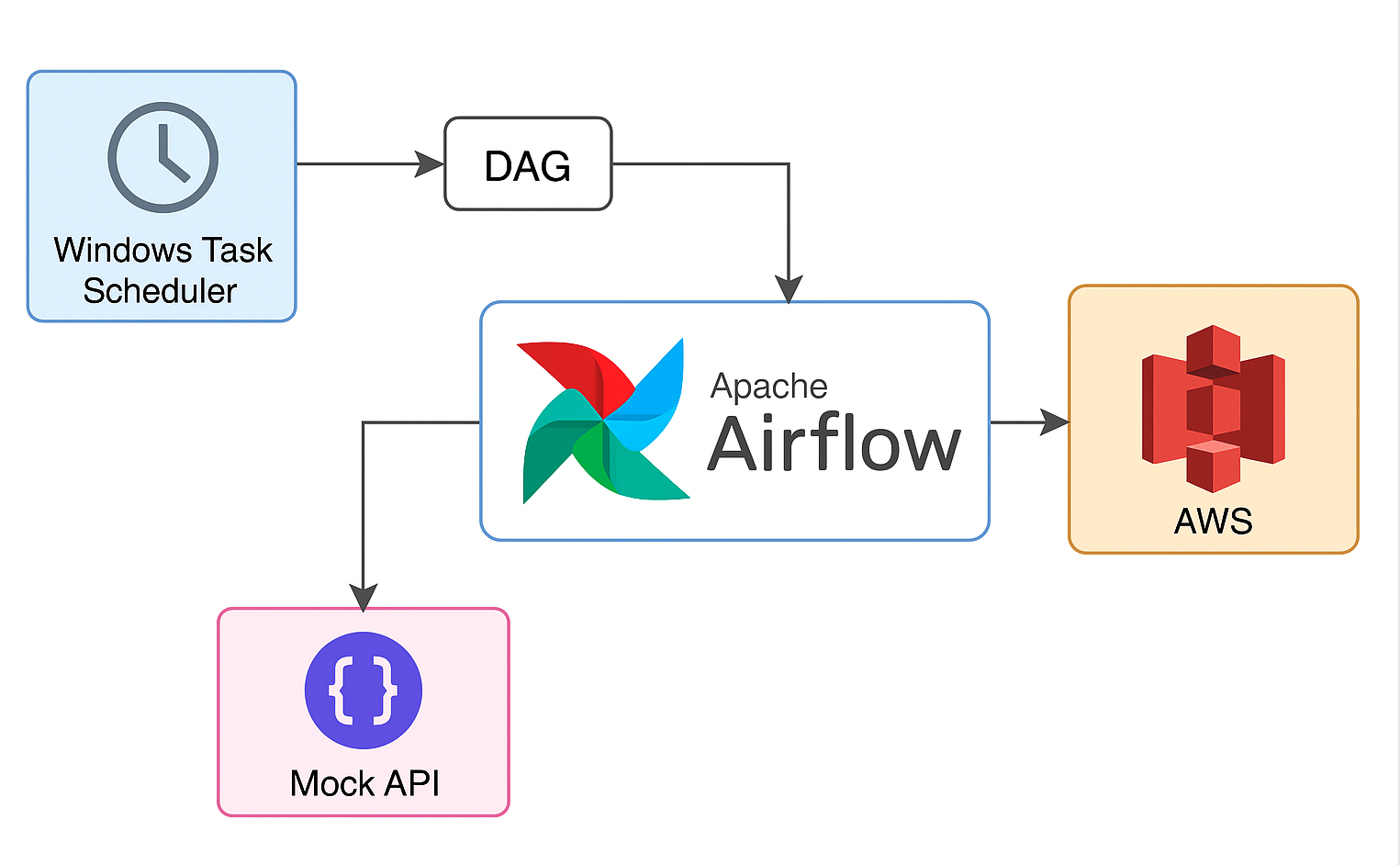
🛠️ Airflow AWS Modernization
Scenario: Legacy Windows Task Scheduler jobs needed modernization for reliability and observability.
📎 View GitHub Repo
Solution: Migrated jobs into modular Airflow DAGs containerized with Docker, storing artifacts in S3 and standardizing logging/retries.
✅ Impact: Up to 50% reduction in manual errors and improved job monitoring/alerting.
🧰 Stack: Python, Apache Airflow, Docker, AWS S3
🧪 Tested On: Local Docker, GitHub Codespaces
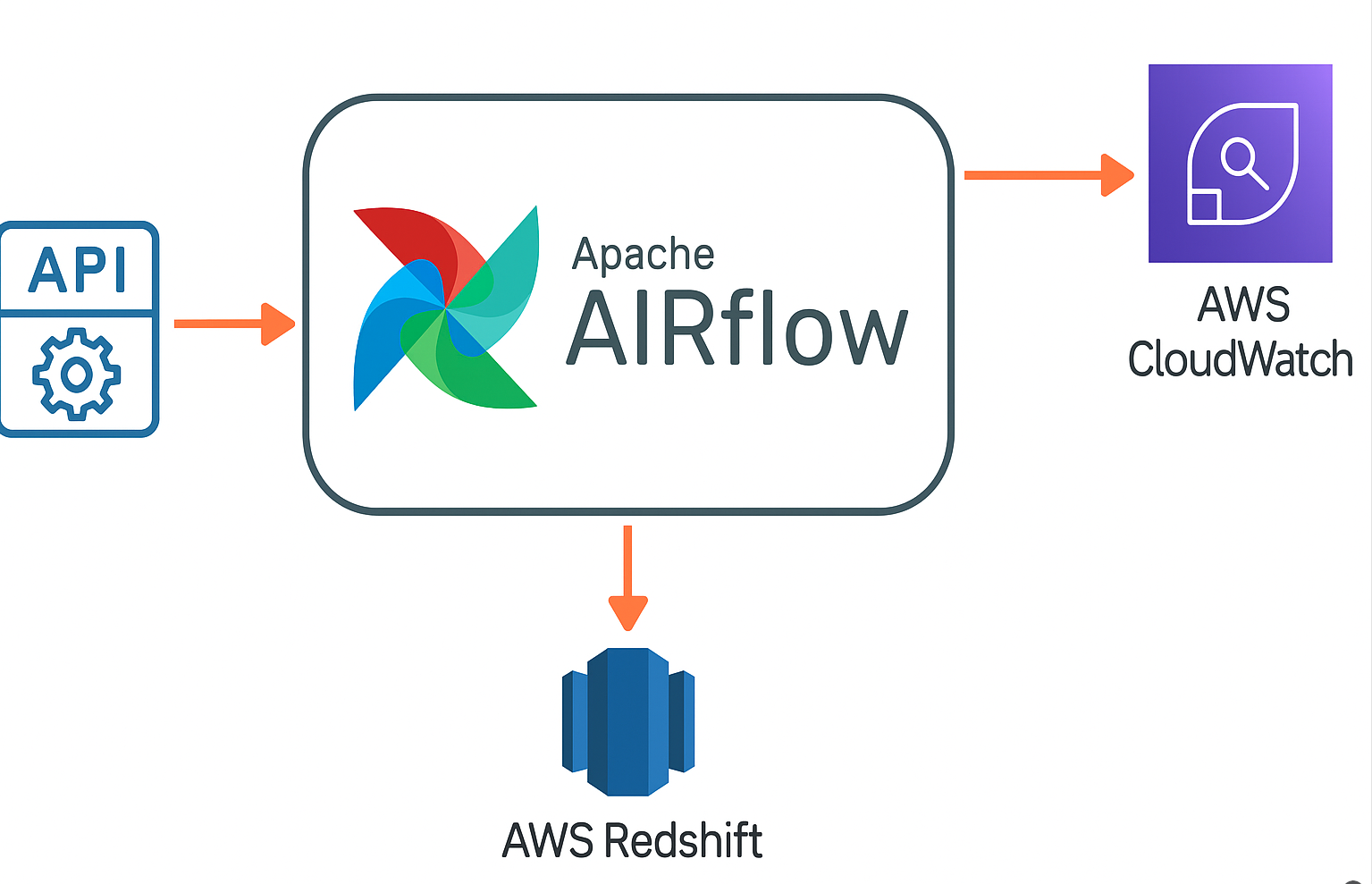
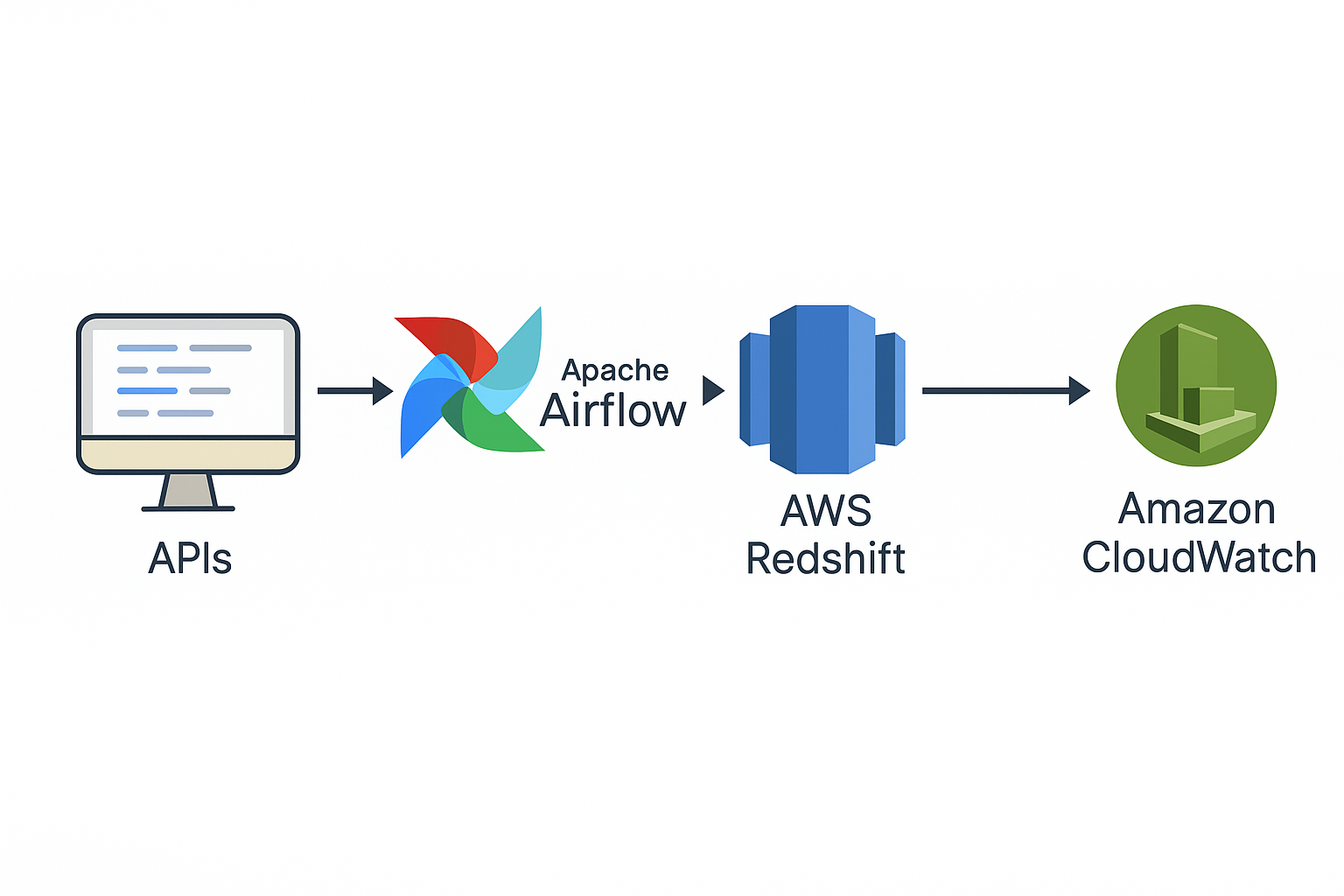
☁️ Cloud ETL Modernization
Scenario: Legacy workflows lacked observability, scalability, and centralized monitoring.
📎 View GitHub Repo
Solution: Built scalable ETL from APIs to Redshift with Airflow orchestration and CloudWatch alerting; standardized schemas and error handling.
✅ Impact: ~30% faster troubleshooting via unified logging/metrics; more consistent SLAs.
🧰 Stack: Apache Airflow, AWS Redshift, CloudWatch
🧪 Tested On: AWS Free Tier, Docker
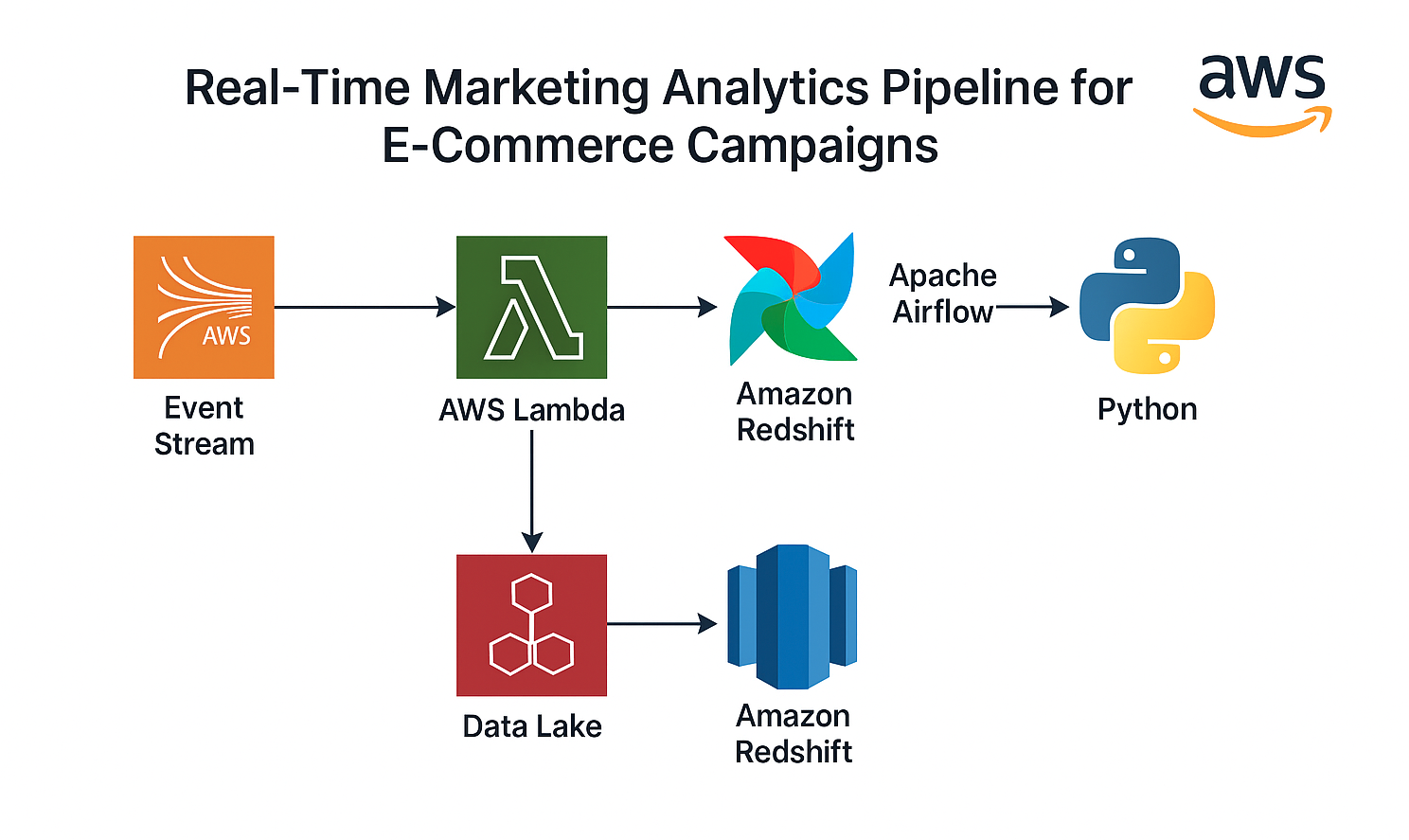
⚡ Real-Time Marketing Pipeline
Scenario: Marketing teams need faster feedback loops from ad campaigns to optimize spend and performance.
📎 View GitHub Repo
Solution: Simulated real-time ingestion of campaign data with PySpark + Delta patterns for incremental insights.
✅ Impact: Reduced reporting lag from 24h → ~1h, enabling quicker optimization cycles.
🧰 Stack: PySpark, Databricks, GitHub Actions, AWS S3
🧪 Tested On: Databricks Community Edition, GitHub CI/CD
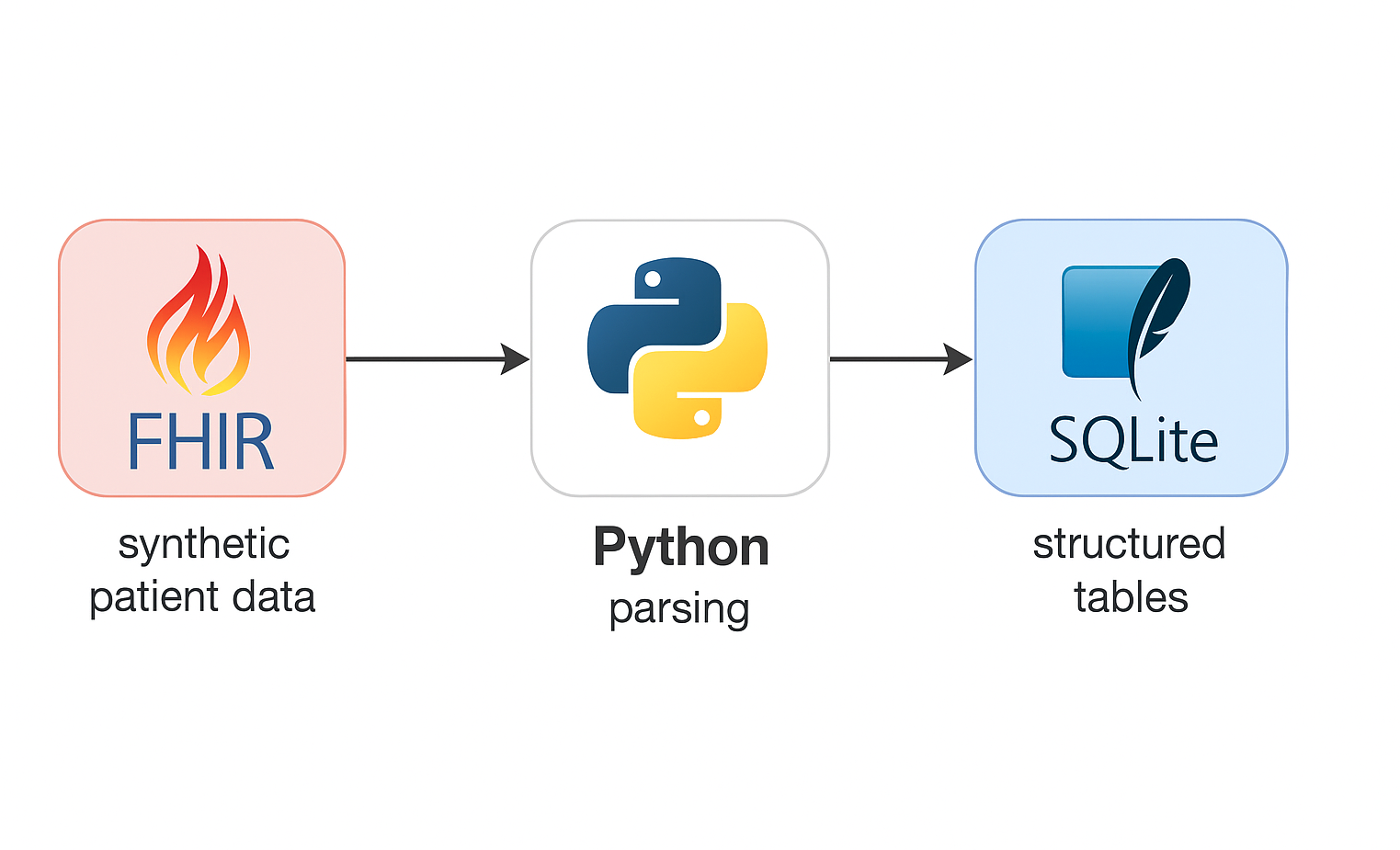
🏥 FHIR Healthcare Pipeline
Scenario: Healthcare projects using FHIR require clean, analytics-ready datasets while preserving clinical context.
📎 View GitHub Repo
Solution: Processed synthetic Synthea FHIR JSON into relational models for downstream analytics and ML.
✅ Impact: Cut preprocessing time by ~60%; improved data quality and analysis readiness.
🧰 Stack: Python, Pandas, Synthea, SQLite, Streamlit
🧪 Tested On: Local + Streamlit + BigQuery-compatible
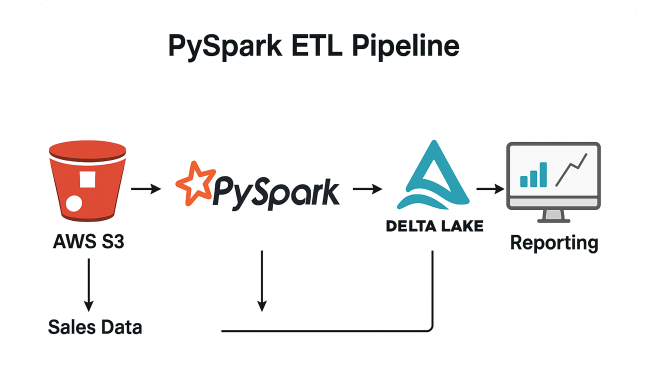
📈 PySpark Sales Pipeline
Scenario: Enterprises need scalable ETL for large sales datasets to drive timely BI and planning.
📎 View GitHub Repo
Solution: Production-style PySpark ETL to ingest/transform into Delta Lake with partitioning and optimization.
✅ Impact: ~40% faster transformations and improved reporting accuracy with Delta optimizations.
🧰 Stack: PySpark, Delta Lake, AWS S3
🧪 Tested On: Local Databricks + S3
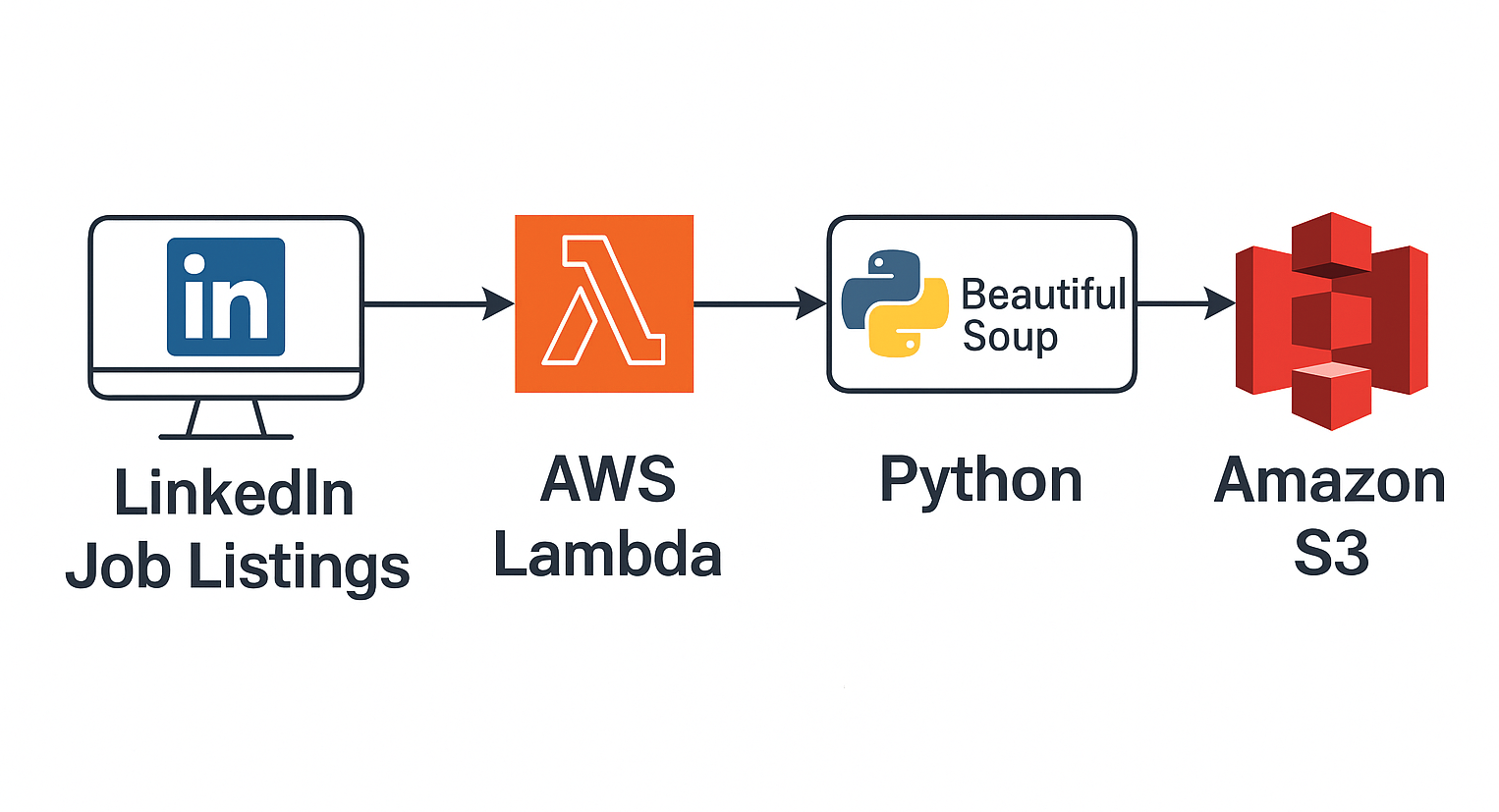
🔍 LinkedIn Scraper (Lambda)
Scenario: Manual job tracking is slow and error-prone for candidates and recruiters.
📎 View GitHub Repo
Solution: Serverless scraping with scheduled invocations and structured S3 outputs for analysis.
✅ Impact: Automated lead sourcing and job search analytics with minimal maintenance overhead.
🧰 Stack: AWS Lambda, EventBridge, BeautifulSoup, S3, CloudWatch
🧪 Tested On: AWS Free Tier